Notes on Unicode
2025-08-04
UTF
- Unicode Transformation Format (UTF) is a way to encode Unicode characters.
UTF-8, UTF-16, and UTF-32
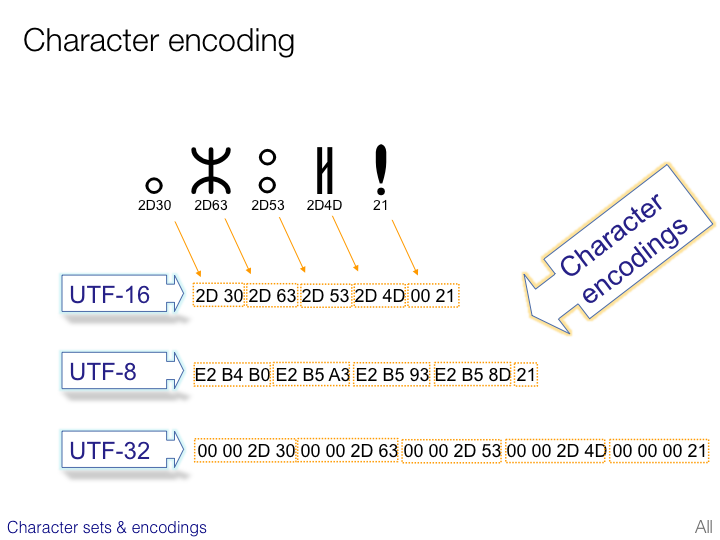
- UTF-8 uses 1 byte to represent characters in the old ASCII set, two bytes for characters in several more alphabetic blocks, and three bytes for the rest of the BMP. Supplementary characters use 4 bytes.
- UTF-16 uses 2 bytes for any character in the BMP, and 4 bytes for supplementary characters.
- UTF-32 uses 4 bytes everywhere.
Run C program with UTF-8 encoded string
#include <stdio.h>
int main() {
// UTF-8 encoded string "A 😀"
unsigned char text[] = {0x41, 0x20, 0xF0, 0x9F, 0x98, 0x80, 0x00};
// Printing the string
printf("%s\n", text); // Output: A 😀
return 0;
}
- Save the above code in a file named
test.c. - Compile it using the command:
cl test.c -o test.exefor Windows (run in cmd) orgcc test.c -o testfor Linux. - Run the compiled program with
test.exeon Windows or./teston Linux - On Windows, if it is run in cmd, ensure the console supports UTF-8 encoding by running
chcp 65001before executing the program. Then I have to runchcp 437to switch back to default to a code page that supports the characters. - The output will be
A 😀, demonstrating that the UTF-8 encoded string is correctly interpreted.